If you’ve been hanging around the open-source AI community (Hugging Face, CivitAI, Reddit) for the last two years, you’ve heard the mantra: “Don’t use .ckpt or .pt. Use .safetensors.”
The community is right. The old standard Pickle is a security nightmare because loading a pickle file effectively allows the file author to execute arbitrary code on your machine. Safetensors fixed this by being a “dumb” format: it’s just a JSON header describing the data, followed by a massive byte buffer of numbers. No code execution, just data.
But “safe from arbitrary code execution” does not mean “safe from everything.”
I recently developed a Python forensic script designed to probe the deeper, less obvious risks of .safetensors files. It goes beyond simple virus scanning and uses statistical and spectral analysis to ask: Is this model hiding something?
Here is a deep dive into the state of Safetensors security, the hidden threats, and how this script attempts to detect them.
Why Safetensors?
Before we break it, let’s appreciate why it exists. Safetensors was built by Hugging Face to solve two problems: Safety and Speed.
- Safety: It replaces Python’s
picklemodule. Pickles are essentially a stack-based virtual machine; when you load a pickle, you are running a program. Safetensors are pure data. Loading them is as safe as opening a.txtfile (mostly). - Speed: It utilizes Zero-Copy (memory mapping). When you load a 10GB model, Python doesn’t copy 10GB of data into RAM. It just tells the OS to map the file to memory, making loading almost instant.
Currently, it is the gold standard. If you are downloading weights for Stable Diffusion or LLMs, you should be using it.
The Problems: If it’s safe, why do we need forensics?
Just because the container doesn’t explode when you open it doesn’t mean the contents are clean. Here are the vectors where .safetensors can still be malicious or problematic:
A. Polyglot Files & Steganography
Since a safetensors file is just a block of bytes, there is nothing stopping an attacker from appending malicious data to the end of the file.
- The Attack: An attacker takes a valid model and appends
malware.exeto the end. The model loads fine (the loader stops reading where the JSON tells it to), but the file is now a “Polyglot.” If the user is tricked into running a secondary extraction script, or if the file triggers a buffer overflow in a parser, the payload executes. - Steganography: The payload can be encrypted and scattered inside the tensor noise.
B. Header Bombs (DoS)
The header is JSON. If an attacker creates a file with a 10GB JSON header containing millions of nested keys, they could crash your RAM when you try to inspect the file.
C. Model Poisoning (Backdoors)
This is the most insidious threat. The file structure is perfect, but the math is poisoned.
- The Attack: An attacker fine-tunes a model to behave normally 99% of the time, but if the prompt contains a specific trigger word (e.g. “James Bond”), the model outputs hate speech or bypasses safety guardrails. This is known as a Backdoor Attack. These attacks often leave mathematical “scars” in the weight matrices.
The Forensic Script: Digging Deeper
My script (safetensors_analysis.py) is a forensic tool that doesn’t just check if the file opens, it checks if the file is weird. It combines structural validation with advanced statistical analysis.
Here is a breakdown of its “features” and the security logic behind them:
Step 1: Structural Integrity (The “Polyglot” Check)
What it does: The script calculates exactly how big the file should be based on the JSON header (Header Size + Tensor Data).
Why it matters: If the file is 100MB larger than the sum of its parts, someone has hidden something at the end. This is a classic hallmark of malware bundling.
Step 2: Entropy Analysis
What it does: It measures the randomness of the data bytes.
Why it matters: Model weights look random, but not perfectly random.
- Standard Weights: High entropy, but usually below 7.9.
- Encrypted Malware: Encryption makes data indistinguishable from white noise, pushing entropy extremely close to the theoretical maximum (8.0 bits/byte). If a specific tensor has an entropy of
7.999, it might not be a tensor – it might be an encrypted payload waiting to be extracted.
Step 3: Benford’s Law Divergence
What it does: It checks the leading digits of the weights against Benford’s Law. In naturally occurring datasets (and often in trained neural networks), the number 1 appears as the leading digit ~30% of the time, while 9 appears only ~5% of the time.
Why it matters: If a hacker generates random noise to fill a tensor, or manipulates weights clumsily, the distribution often flattens (1 appears as often as 9). A high “Benford SSE” (Sum of Squared Errors) suggests the data is artificial or tampered with.
Step 4: Spectral Anomaly Detection (The “SOTA” Technique)
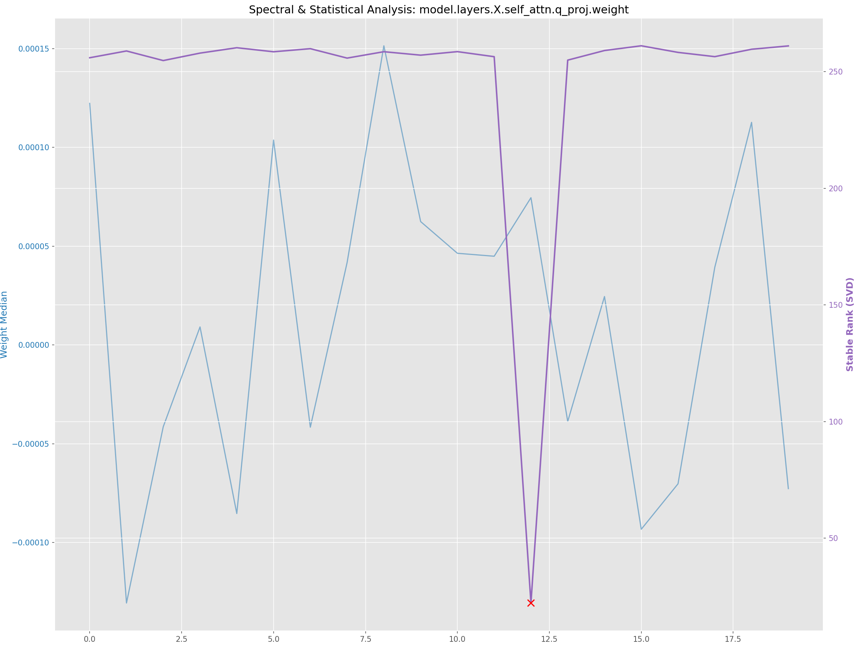
What it does: This is the most advanced part of the script. It uses Singular Value Decomposition (SVD) to analyze the “Stable Rank” of the weight matrices.
Why it matters: Recent research (e.g. Spectral Signatures in Backdoor Attacks) suggests that when a model is “poisoned” (trained on bad data to create a backdoor), the corrupted weights often exhibit a spectral spike, a dominant direction in the matrix that corresponds to the backdoor trigger. The script flags tensors that have an unusually low Stable Rank compared to their peers, potentially identifying these “poisoned” layers.
Limitations: It’s a tool, not a verdict
While this script is powerful, it is not a magic bullet.
- False Positives (Quantization): The script explicitly has to handle “Quantized” models (Int8/Int4). Quantization destroys the natural distribution of weights. A quantized model looks like high-entropy noise and violates Benford’s law naturally. The script attempts to ignore these, but it can be tricky.
- False Positives (Architecture): Some valid architectural choices (ike Input Embeddings or Output Heads) naturally have weird spectral signatures. To really dial down structural false positives, we would need a ‘whitelist’ of spectral signatures for established architectures. If the script could recognize that a specific skew in Layer 0 is just a standard quirk of Llama-3, and not a tamper attempt, we’d see far fewer false alarms. To be implemented in V2.
- It doesn’t “clean” the file: It only alerts you. It cannot tell you what the payload is, only that the math looks suspicious.
When is this useful?
You don’t need to run this on every diffusion_pytorch_model.safetensors you download from the official repo. However, this tool is valuable for:
- Model Auditing: If you are a platform host (like CivitAI or a corporate model hub), you need to scan user uploads for polyglot files to prevent distribution of malware.
- Supply Chain Verification: If you are downloading a model from a generic user (“User123”) that claims to be a finetune of Llama-3, this script can help verify if the weights look consistent with a real training process or if they are just random noise/tampered.
- Steganography Research: Detection of watermarks or hidden messages in weights.
Conclusion: Trust, but Verify
The transition from Pickle to Safetensors was a critical first step in maturing the AI ecosystem. It successfully closed the door on the most obvious vulnerability: arbitrary code execution upon loading. In that sense, the “State of the Art” is working, we no longer have to worry that a simple torch.load() will ransom our hard drives.
However, as we have explored, a safe container does not guarantee safe contents. The threats have simply evolved from the system level (viruses, RCE) to the model level (steganography, poisoning, and supply chain attacks). A .safetensors file might not be able to execute code, but it can absolutely carry a dormant payload or a mathematical backdoor designed to trigger specific, malicious behaviors.
This is where forensic tools become essential. By leveraging specific techniques we can peer past the JSON header and into the noise of the tensors themselves. While the script has its limitations, particularly with quantized models and false positives inherent in statistical analysis, it represents a way to shift in mindset.